The performance of an eCommerce solution increases with concern as the intended audience opens up to non-structured public traffic. Reduction of the volume of support calls is enhanced when performance is optimized.
If development were to build directly into a production ready environment, then key performance indicators could be contained along with all regular unit testing. This is not the case for regular development cycles which leads towards a performance optimization plan. This plan would need to incorporate optimizing the solution beyond the means of development cycles. The advantage of having a performance cycle imposed into the delivery of an eCommerce solution and/or enhancement is that the team also increases their observed knowledge of how the system operates. This intellectual capital gained from learning system capabilities also provides input for future development enhancements.
As previously stated, the performance optimization efforts may not be able to tie directly in earlier states of development processes, however, there is still some mechanisms that should be considered in earlier stages of a project:
Development preparation
The development phase should ensure to include optimization with governance around using parametric queries over concatenated queries. That is basic knowledge in the development community. Other than newly created queries, all new and existing data access through the application should enable the WebSphere Commerce data cache and optimize the configuration.Once the data cache is enabled, then additional unit testing should be employed during the development cycle to ensure integrated applications still capably pull the intended data.
A planned application layer caching strategy which includes both TTL and invalidation mechanisms that can be automated and managed. The Content Delivery Network can also cache static content which could prevent up to 20% of all online activity from dependency to call the origin application landscape. Specifically for IBM WebSphere Commerce, the out-of-the-box dynacache capabilities can be easily incorporated into a solution, there are sample cache configuration files within the base samples directory.
Database preparation
For all new tables imposed on the schema, there should be monitoring of tablespace usage and/or defining new tablespaces to loosely couple memory footprint between the new tables and existing tables. The indexes for all tables should also be reviewed and refreshed with scheduled maintenance which will include all other ongoing clean-up routine. Also obsolete and aged data should be cleaned through database clean-up jobs which should be reviewed on a quarterly basis.Performance Assessment Process
With confidence that the development and database administration preparation is fulfilled, then the performance assessment can focus entirely on the system related metrics. Not suggesting that performance will not find challenges imposed through development, however, the effort to minimize the impacts will speed the process.With performance scheduled into a project as a phase or parallel path, there are many repeated cycles and iterations. This is based on the premise that any tuning or optimization introduced throughout the performance path needs to be precisely defined. That way, those metrics changed or tuned contribute towards an enhanced understanding of all the system parameters and indicators.
Below is a high level diagram of a suggested performance assessment process:
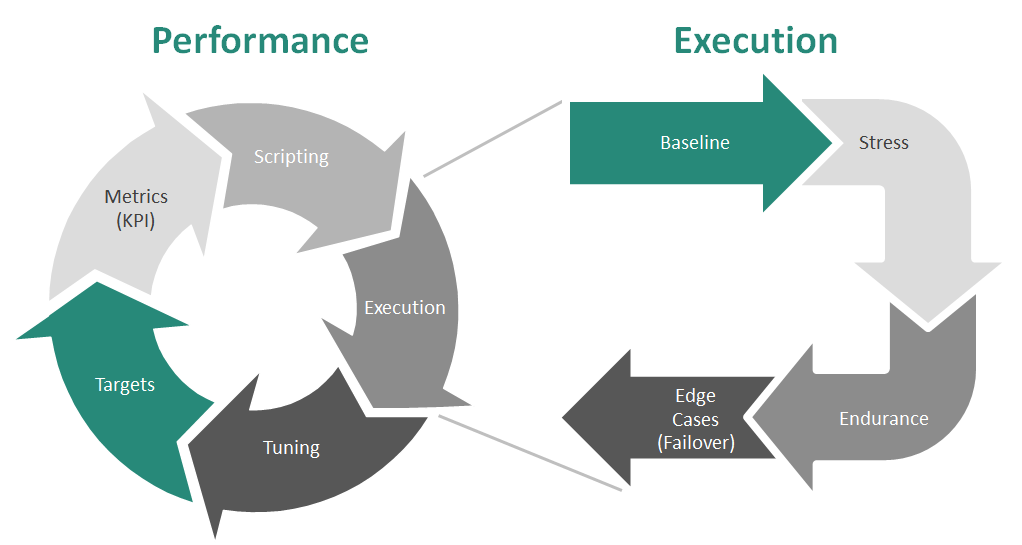
The cyclic depiction on the left indicates the many phases within the performance assessment process. The cycle can be repeated many times and in most cases with eCommerce solutions that have high transactions, there will be many repeated cycles over the life-cycle of delivery.
Targets
The process starts with determining the targets which includes capturing those non-functional requirements. Targets are influenced on factors such as return on investment, User Experience and infrastructure capabilities. These targets are input into the Key Performance Indicators.Metrics
The basis for key performance indicators in an eCommerce solution is the public traffic page views, shopping cart views and completed orders, all of which are measured per second, per hour at an average rate as well as peak. The peak rates are the best case performance optimization strategy so that campaigns whether controlled or based on event can be managed through the system landscape.Scripting
Once the metrics are prioritized, all of the interfaces that the public traffic encounters is stacked into various user workload groups. Those groups can be either registered or guest users that hit various features such as search, registration, general browse, pending order creation (cart), checkout and order submission. Each of these areas are given weight and distributed in such a way to best reflect the expectations of actual eCommerce traffic. Some of the expected weights can veer towards subjective determinants or factually based on objective analytic historical reports.The scripts are written into a tool which can execute the operation automatically. There are such tools such as Apache jMeter or LoadRunner which can supplement this process for your team. Each individual script can be considered as a single operation such as search, or browse or checkout.
For each individual operation, there is input data that it must follow in order to execute. Most automated test tools provide a mechanism to systematically input data as input elements of the script.
That test data bucket of elements must be prepared prior to the execution.
The test tool which can understand these scripts would also need to be configured to operate with the environment.
Execution
There are some performance test tools which can automatically execute the scripts to guide the simulation of predefined user workloads against the environment. As the tool runs, metrics are captured such as the CPU usage, memory utilization and operation completion response times.As per the diagram above, there are many different iterations of the execution phase:
- Baseline
- As with any statistical analysis, there requires a control group to compare results in order to dervive significant and confidence that an optimization path is realizable
- Stress
- Minimal stress can be attributed to those tests which directly meet the targets. Incremental stress testing can be used to equally monitor the response from the system and the application
- Endurance
- Testing that directly aligns with the actual intended operational activity of the eCommerce solution can capture significant response and demonstrate optimal effectiveness
- Edge
- Edge cases such as failover testing can align with expected support processes
The response metrics captured during execution of these iteration phases can be used to compare against those different loads in conjunction with the various user workload groups.
On top of capturing response metrics from the tool, the team can also benefit from profiling of the system and code and align with the expected KPI's. Plus there are those support groups monitoring tools which can be reused to support findings during performance assessment.
The mutually exclusive monitoring tools can be groups into the following application layers:
- Analytics
- Adobe Analytics or SiteCatalyst
- Google Analytics
- JVM Monitoring
- Database
- native db server performance monitoring tools
- Operating System
Once execution is completed, the results are captured and then analysed by the team. The analysis turns into input for the tuning proposals.
Tuning
Once tuning proposals are accepted, then the entire process is repeated so that the new captured response times are compared against the controlled previous result set.Based on the new iteration of tests, then confidence increases that performance optimization can be achieved.
Below are some notable tuning adjustments that may be considered, it would be a good approach to keep track of these parameters throughout the process:
- OS level
- CPU overhead to accommodate JVM Heap size for large pages
- TCP/IP timeout to release connections
- Web Layer
- Number of processes allowed
- Idle thread maximum allowance
- Enabling caching of static content. May also or exclusively use the CDN as the static cache is it has invalidation tooling. Assuming that the CDN is operational. See CDN solutions surch as Zenedge and Akamai
- Application Layer settings
- Database connection pool settings (JDBC)
- align connections with the web container threadpool size
- Statement Cache - Prepared statement cache depends on the usage of parametric queries used in the code
- Load Balancer
- Depending on whether reusing the firewall as a load balancer or using a dedicated device may impact the design of health checking.
- Cache Settings
- Disk offload location needs to manage disk memory. Also, using /tmp directory conflicts with other OS management
- Search layer (e.g. SOLR)
- JVM settings
- Web Container Threads is a sensitive setting due to synchronization issues under high load. Multi-threading eliminates synchronization and contention issues.
- Database Layer
- Database Manager
- Number of Database - tighten this value to inform database management of resources is redundant
- Database Configuration
- Locklist to align with the locks required by the eCommerce application
- Sortheap - may be required if queries depend highly on sorting logic
- Bufferpool thresholds for higher transaction workloads
- DB Self Tuning Features may conflict with raising bufferpool or sort heap sizes based on fluctuating activities. This could be controlled through endurance/stress testing
It should be noted that those monitoring tools that run during the performance assessment process should remain in the production environment ongoing. That way, real time traffic can be monitored and feedback and derive into targets which can be used as input for future isolated performance assessment process.




